Understanding Hermes From An Agentic Memory Perspective
1. Introduction
Anyone who has spent time experimenting with autonomous agents eventually runs into the same frustration: they forget more than they should.

Current agents are more like demos than reliable systems. They perform well in short, curated examples, but once placed under real constraints such as long tasks, repeated usage, or evolving environments they start repeating the same mistakes. The problem is not intelligence. The problem is remembering things, the problem is memory.
The field is slowly recognizing this. Recent progress in agent design is less about making models "smarter" and more about giving them mechanisms to remember.
This is the motivation behind Hermes Agent by Nous Research, an emerging open alternative to systems like OpenClaw. Hermes attempts to treat memory as a first-class component of the agent architecture. Instead of bolting learning on as an afterthought, it tries to embed memory into the core design.
This essay explores how that system works.
2. A Bird's-Eye View
If an agent is expected to remember and learn in a human-like way, it must manage three different kinds of information.
First, it must track the current task: the ongoing conversation, tool calls, and intermediate reasoning. This is the agent's working context.
Second, it should recall previous sessions. If the agent solved a difficult Docker debugging problem last month, it should be able to retrieve that experience.
Third, it should accumulate long-term knowledge about its environment and its user: preferences, conventions, and recurring patterns.
Hermes addresses these needs through a layered architecture composed of three memory systems.
3. The Three Layers of Memory
Hermes' design mirrors the categories we just described. Each layer serving a different purpose and operating at a different time scale.
3.1 Working Memory
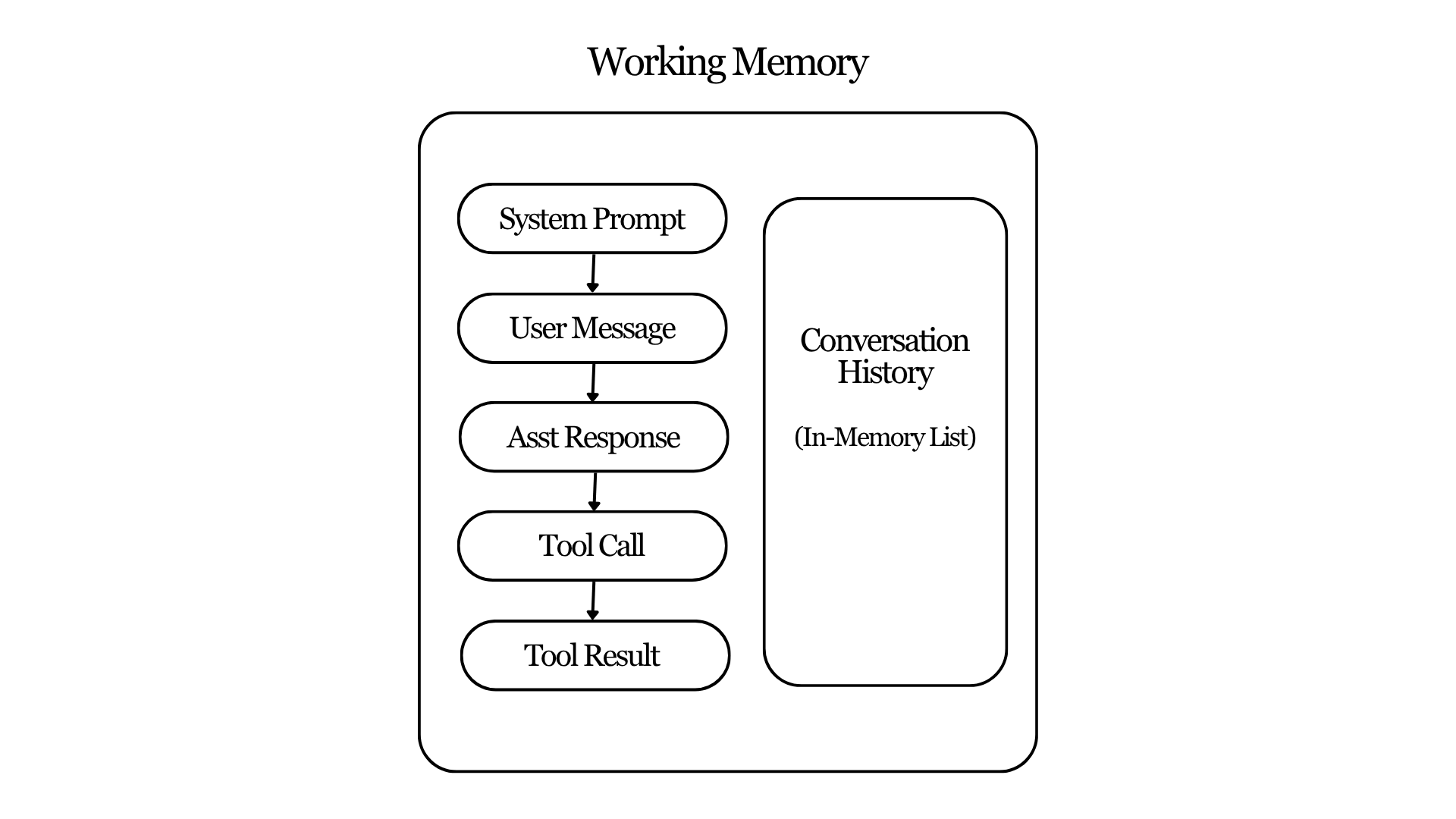
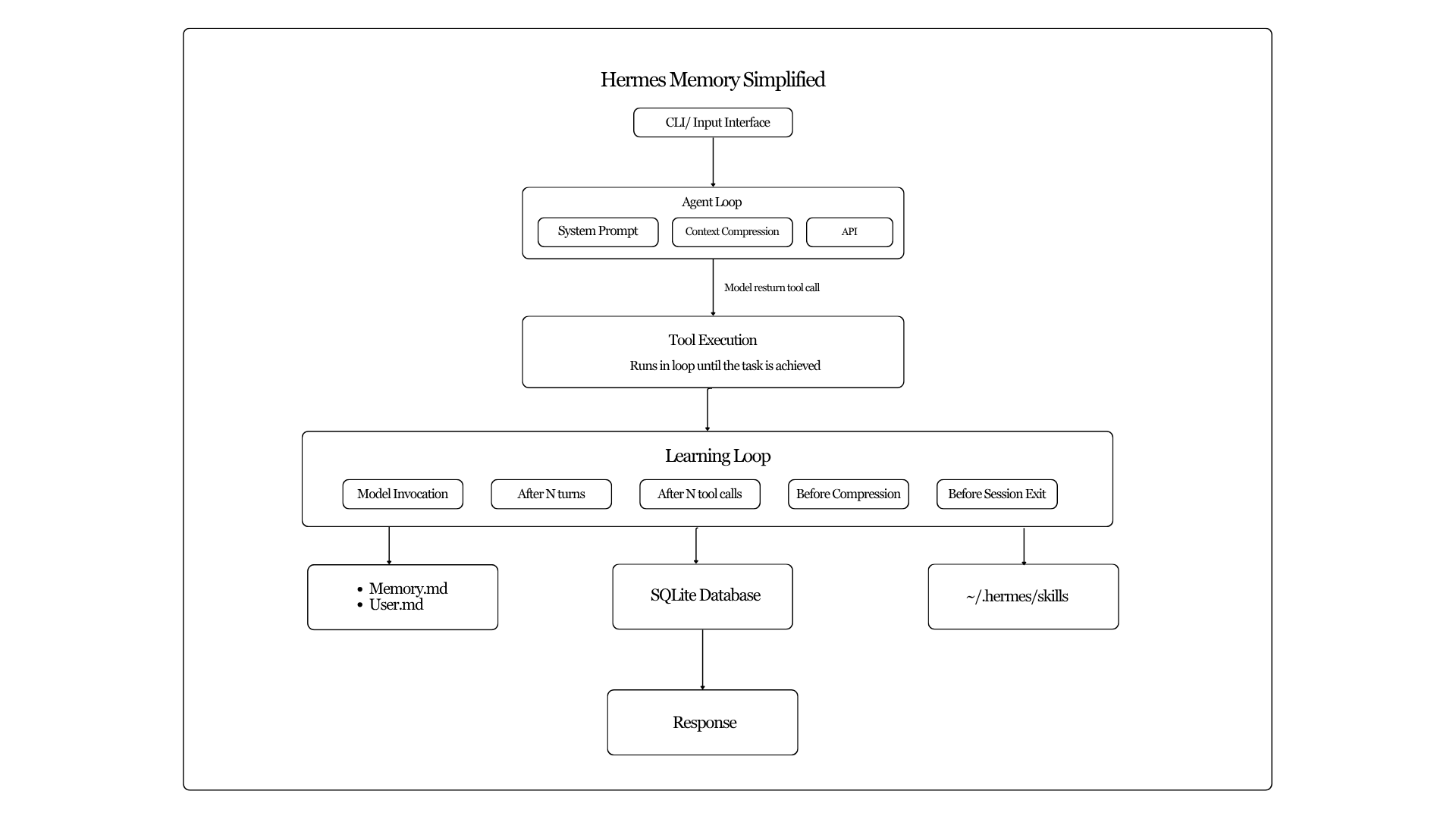
Working memory represents the agent's awareness in its current session and the task that it is performing. Implementation is intentionally simple: an in-memory list. Every message that appears in the conversation from. system prompts to tool call results are appended to this in-memory list.
This same structure becomes the conversation history sent to the model API. As long as the conversation continues, the list grows. Working memory therefore mirrors the exact sequence of events that occurred during the session.
3.2 Episodic Memory
When a session ends its working memory disappears. Episodic memory exists to preserve it. Hermes stores session history in a local database using SQLite. On top of that Hermes also employs full-text search powered by FTS5.
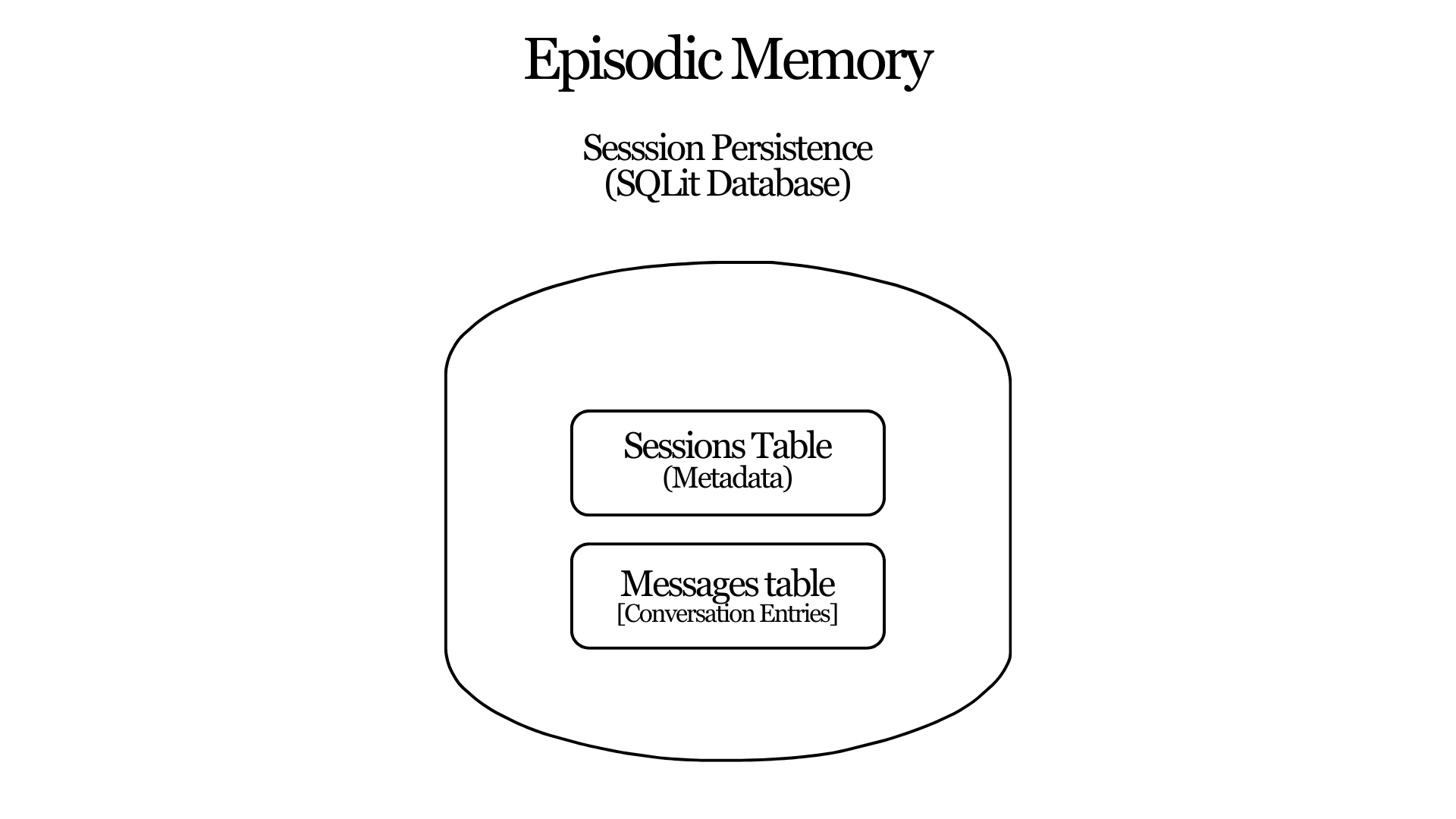
Every message, tool call, and token count is written to disk. But why use a database instead of simple files? The answer is simple: A database allows the agent to attach additional information to each session metadata such as timestamps, model configuration, and billing details. This wouldn't have been possible with a single markdown file.
Hermes organizes this data into two tables:
Sessions: metadata about the session
Messages: the conversation entries themselves
FTS5 indexes the message content, allowing the agent to search past interactions efficiently. This becomes important when the agent needs to recall relevant experience from previous sessions. Working of FTS5 is explained in further sections.
3.3 Long-Term Memory
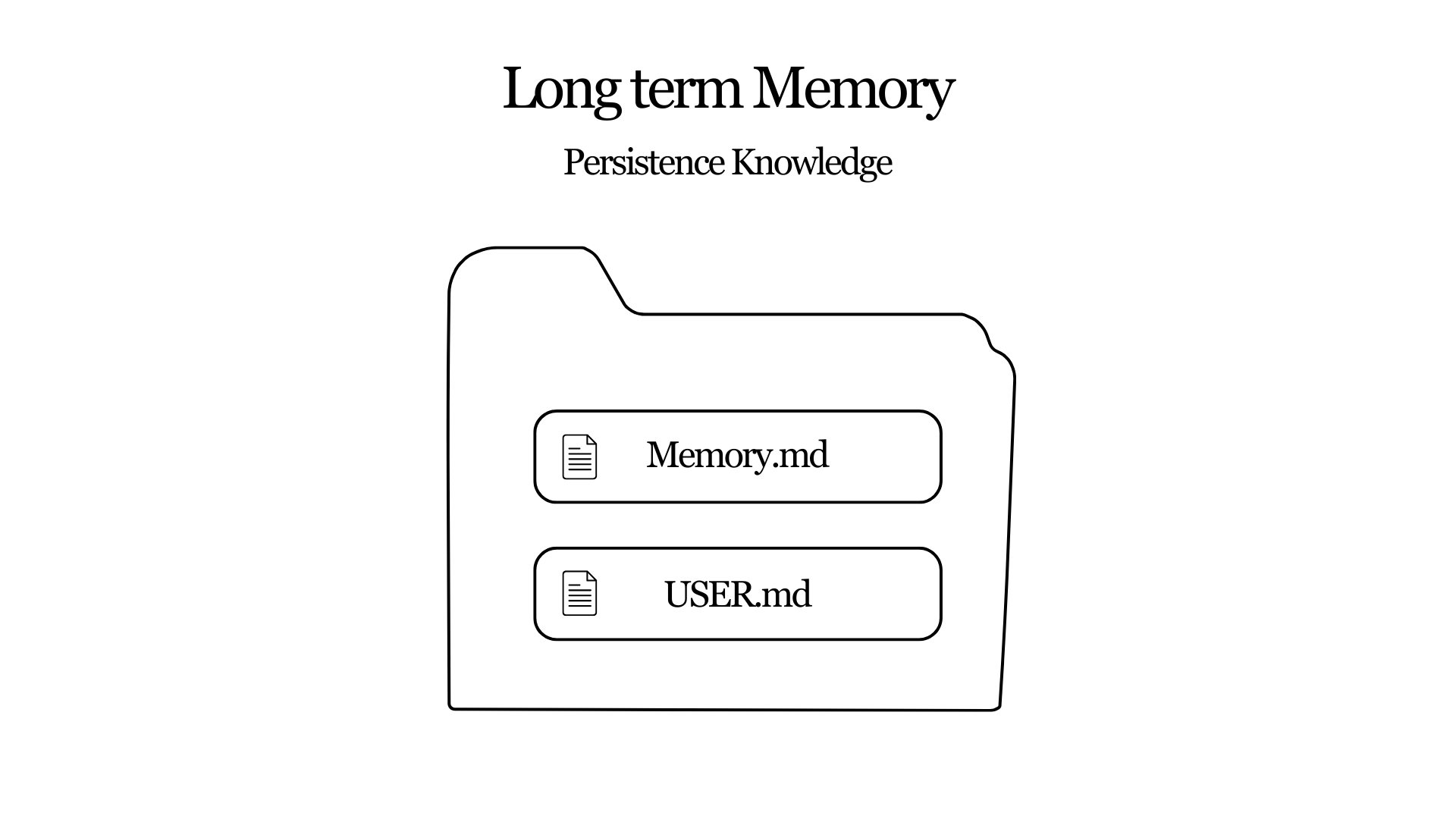
The outermost layer stores persistent knowledge. Instead of using a structured database schema, Hermes deliberately keeps this layer simple: plain Markdown files stored locally.
Two files hold the information:
MEMORY.md: knowledge about the environment, tools, and conventions
USER.md: knowledge about the user's preferences and habits
Entries are separated by delimiters and stored as plain text. There is no strict schema. The agent can append, replace, or remove entries through its memory tool. The design is intentionally lightweight. Long-term memory behaves less like a database and more like a continuously evolving notebook.
4. Memory Writing: How Agents Learn
Humans rarely "decide" to learn something formally. Instead, we subconsciously make a note in our memory. To mimic this to some extent Hermes has employed 5 Triggers that determine when knowledge should be stored. This triggers are explained below
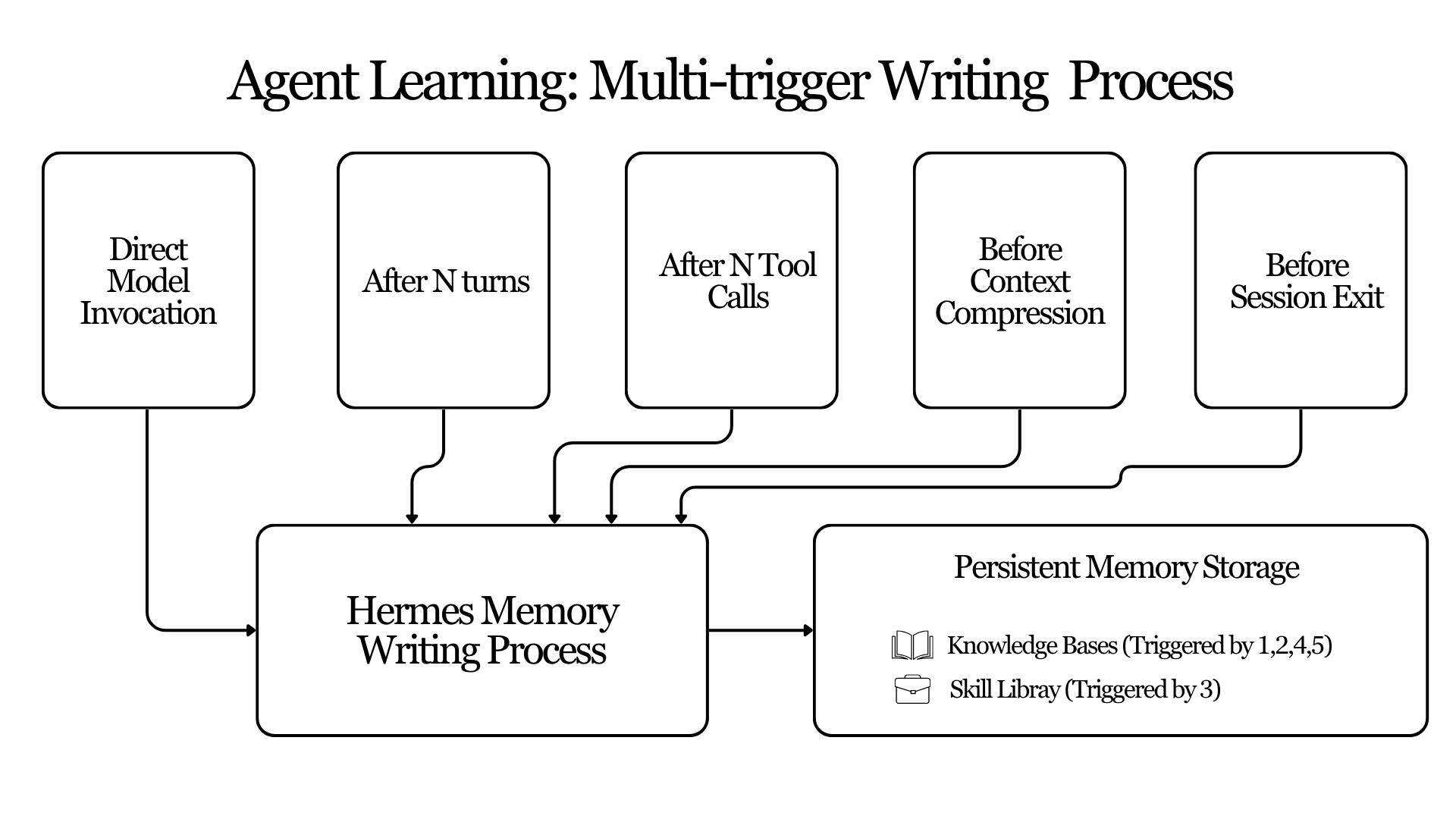
Trigger 1: Direct Model Invocation
The simplest case occurs when the model itself decides that something is worth remembering. Hermes exposes a memory tool that allows the model to write entries into its persistent files. The model can add or replace information when it detects a pattern or learns a useful detail.
Trigger 2: Turn-Count Nudge
Hermes also includes a passive learning mechanism.
After a certain number of user turns pass without any memory activity, a background thread prompts the agent to review the conversation and decide whether something should be stored. This often captures small but meaningful details such as user preferences.
Trigger 3: Iteration-Count Skill Nudge
A parallel system exists for skills. Instead of counting user turns, Hermes tracks tool iterations. When the agent performs a substantial amount of tool-driven work without updating its skill library, another review is triggered.
The agent looks for patterns such as:
- methods that required multiple attempts
- solutions discovered through experimentation
- workflows that could be reused later
If such a pattern exists, the agent converts it into a skill.
Trigger 4: Flush Before Context Compression
Conversations eventually become too long to fit inside the model's context window. Before Hermes compresses older messages, it performs a synchronous memory flush. The agent reviews the conversation and extracts important knowledge that might otherwise be lost.
This is the only memory operation that intentionally pauses the conversation loop.
Trigger 5: Flush Before Session Exit
A final safeguard occurs when a session ends. Whenever a command-line session resets or the gateway terminates an idle conversation, Hermes performs a final memory review using the full transcript. This guarantees that valuable information is not discarded simply because a session ended.
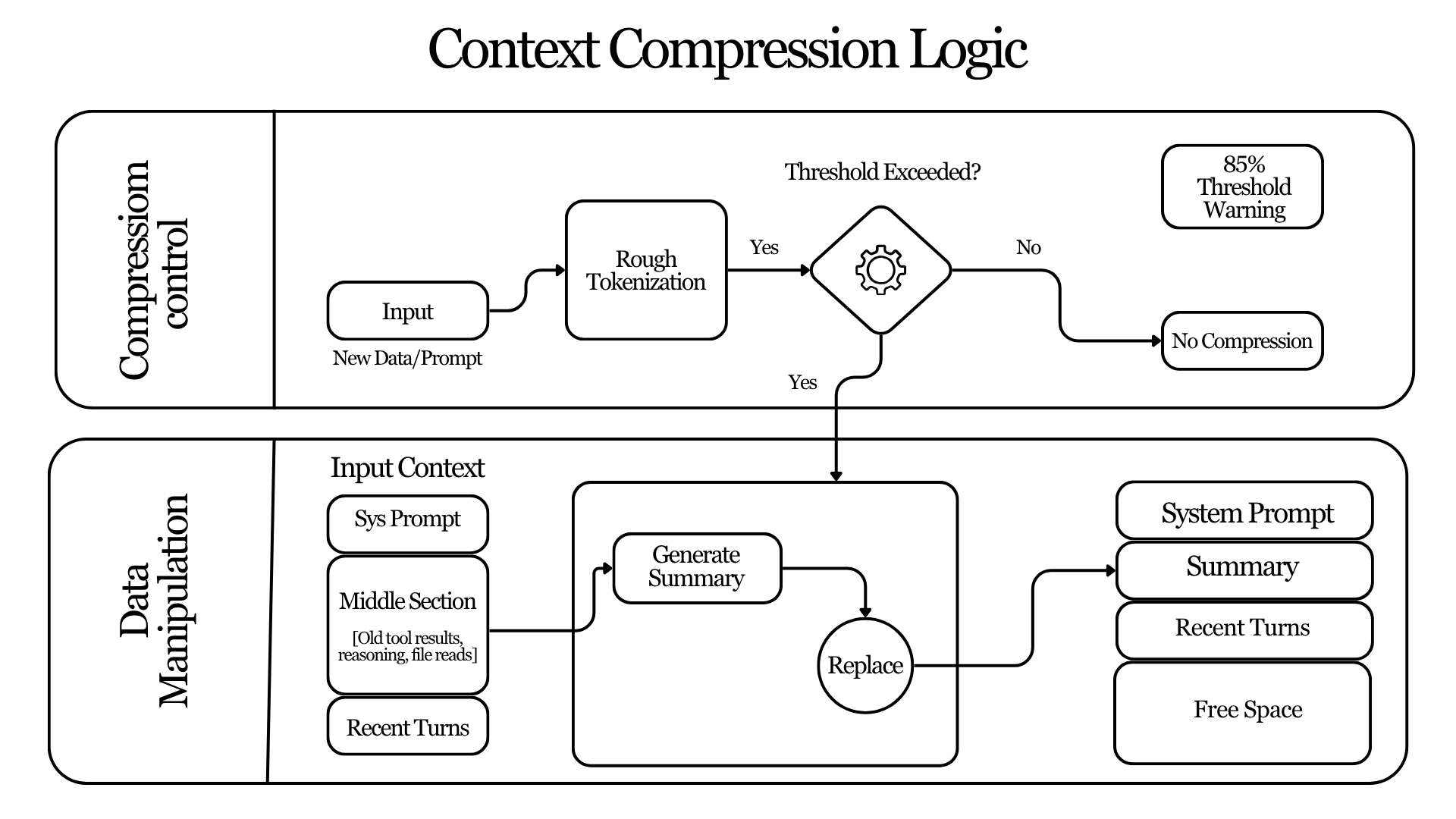
5. Context Compression: The Memory Compactor
We know that all LLMs operate within a finite context window. As discussions grow longer, working memory begins to accumulate tool results, file reads, and exploratory reasoning that are no longer relevant. Without intervention, the context eventually exceeds the model's limits.
Hermes solves this using a context compressor. Instead of discarding information, the system removes the middle section of a conversation and replaces it with a structured summary generated by a language model.
Compression is triggered when two conditions are met:
Token threshold.
Compression activates when the total tokens reach a configurable percentage of the model's context window (by default, 50%).
Preflight estimate.
Before each API call, Hermes performs a rough tokenization estimate. If the estimate exceeds the threshold, compression begins immediately.
Users receive a warning when usage approaches 85% of the threshold so they can anticipate compression. One principle governs the entire design: never break the prompt cache.
The early portion of the conversation, especially the system prompt, remains untouched. Hermes therefore compresses only the middle region of the dialogue.
6. Session Search and Cross-Session Memory
Stored sessions are only useful if they can be retrieved. Hermes solves this through a layered retrieval pipeline built around SQLite and FTS5.
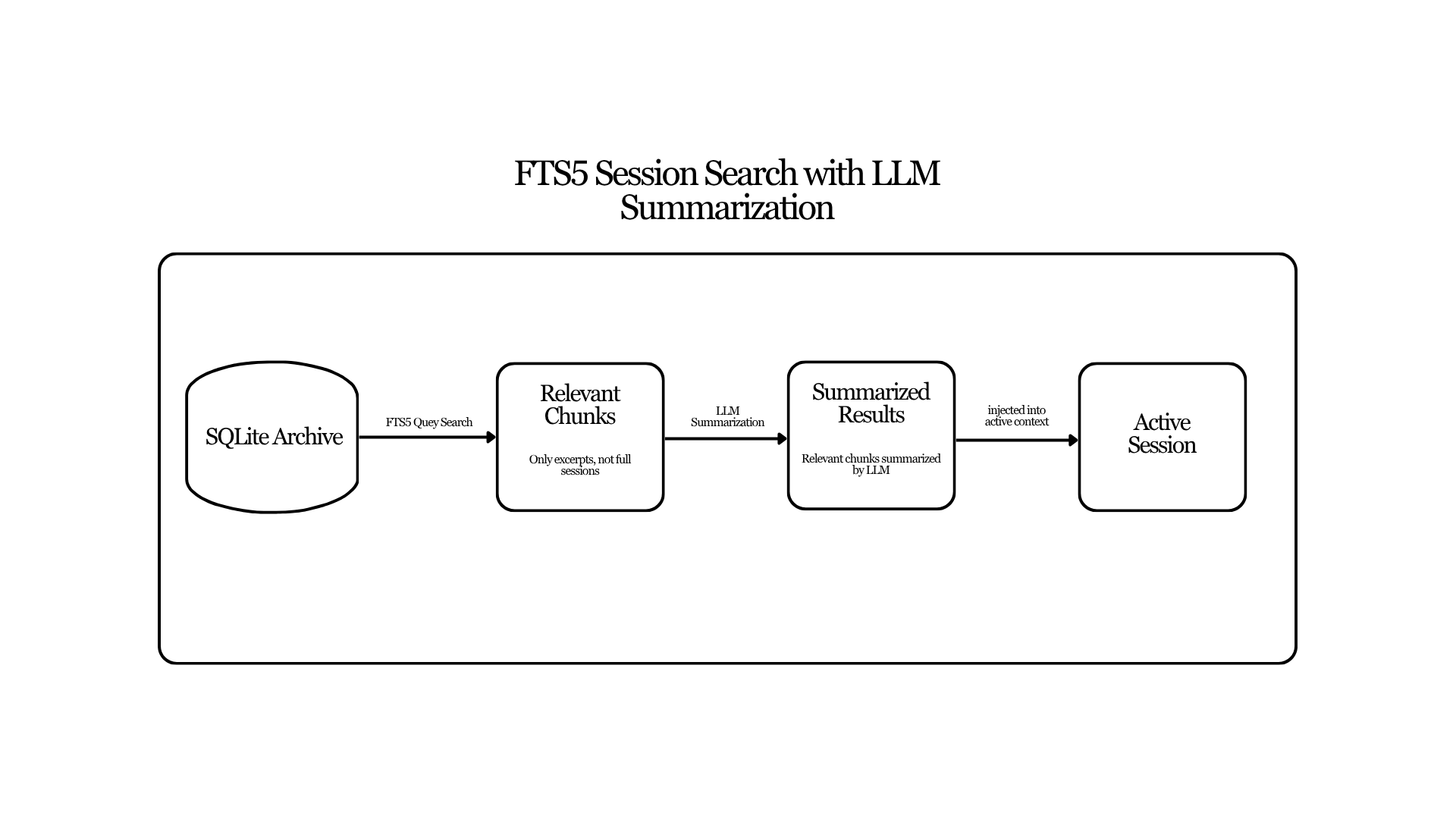
6.1 Database Foundation
All messages are persisted in a local database at ~/.hermes/state.db. The FTS5 index tracks message content and remains synchronized with the base table through automatic triggers. This allows Hermes to perform fast full-text searches across the entire conversation history.
6.2 Query Sanitization
FTS5 uses a specialized query syntax. Raw user input can easily produce malformed queries. Hermes therefore runs search requests through a sanitization pipeline that preserves quoted phrases while removing unsupported characters.
6.3 Retrieval Pipeline
When the search tool runs, Hermes performs several steps:
- Retrieve up to fifty matches ranked by BM25 relevance
- Map matches to their parent sessions
- Deduplicate results
- Extract relevant text segments
- Summarize the findings with a language model
If the search tool is called without a query, Hermes simply returns metadata for recent sessions.
6.4 Parent Session Resolution
Delegated tasks often create child sessions that contain internal agent activity. Hermes walks the parent_session_id chain until it reaches the original root session. This ensures the retrieved context corresponds to the user-facing conversation rather than internal tool chatter.
6.5 Transcript Summarization
Session transcripts can exceed 100,000 characters. Instead of returning the full text, Hermes summarizes relevant segments using a lightweight model. The result is a concise recap that captures the essential insight without overwhelming the context window.
6.6 External Memory Providers
Hermes also supports pluggable external memory systems. Backends such as RetainDB, OpenViking, and Honcho can be integrated to extend the memory layer beyond local storage.
7. Conclusion
Most agent discussions focus on models. Bigger models. Better reasoning. Longer context windows. But the real limitation of agents was all along a memory and orchestration problems..
Hermes approached this problem from a different direction. Instead of treating memory as an optional feature, it treats memory as infrastructure.
- Working memory tracks the current task.
- Episodic memory stores past sessions.
- Long-term memory accumulates knowledge about the environment and the user.
On top of that, Hermes adds mechanisms that decide when learning should occur: background nudges, skill detection, compression flushes, and session-end reviews. These systems slowly convert temporary conversations into persistent knowledge.
None of these pieces are individually revolutionary. Databases, full-text search, prompt caching, and markdown files are all fairly ordinary technologies. What is interesting is how they are combined.
The result is an agent that does something most agents still struggle with: it improves over time.
This is still an early step. Hermes does not fully solve agent memory. The harder problems still remain unsolved, we still don't have our Jarvis but one day we might have one. And We all will be waiting for that.